First things first. I've stated that you should drop everything and install Graphite. If you didn't already, please do that now. Go ahead, I'll wait.
Good? Good. I don't frequently insist on anything like I do with Graphite. There's a lot of reasons for that. If you don't believe me, please see @obfuscurity's awesome Graphite series on his blog.
When you get back we'll talk about how to monitor ElasticSearch with Graphite for fun and profit!
Monitoring ElasticSearch : Baseline
Today's silly graphite trick involves monitoring for ElasticSearch. There are a number of solutions available for live monitoring of an ElasticSearch cluster, BigDesk and Head are great solutions for running and monitoring your cluster real-time.
However, BigDesk lacks the customization and the incorporation of data from other sources. Graphite makes it so brain dead simple to store and track metrics that it's really only your own fault for not tracking the surface area of the illuminated portion of the moon. Then you really can track your metrics against phases of the moon! Graphite also allows you to store your raw data and manipulate it for display purposes.
I strongly recommend you consider Diamond for polling system metrics and outputting them to your Graphite infrastructure. After a lot of fiddling with the collectd graphite plugin, we were forced to go with Diamond because the collectd plugin required a carbon-aggregator to translate and flatten our metrics namespace into a sane and useable format. That worked at first, but running hundreds or thousands of servers through a carbon-aggregator that has to manipulate almost every metric doesn't scale. Even with 20 aggregators running on multiple collectors, we struggled to map the data real-time. Diamond allowed us to scale horizontally by mapping metrics on the end point hosts and shipping them pickled to a carbon relay.
Getting ES Metrics into Graphite
So, use Diamond to get base system data into Graphite. Now, we need to get some insight into the ElasticSearch daemon itself. I looked a while back and was unable to find anything useful, so I made it myself. ElasticSearch provides a number of API calls to retrieve statistics, but I chose the Node Stats as a starting point for pulling data out of ES.
At the time, we weren't sure that Graphite was going to displace Cacti as our monitoring solution (well, I was) so my perf_elastic_search.pl script will output the metrics in the correct format for Graphite or Cacti. Though Cacti output is untested because I gave up after 3 or 4 hours of trying to figure out how to get data into Cacti.
I recommend running this on the ElasticSearch nodes with the --local options specified on a 1 minute cron job:
* * * * * /path/to/perf_elastic_search.pl --local --carbon-base=es
My Silly Trick
Now, if you read through Jason's awesome series of posts, you're probably able to do a lot of cool stuff with Graphite. If you're studious, you can do something far cooler than the parlor trick I want to show now! Enough suspense, here it is:
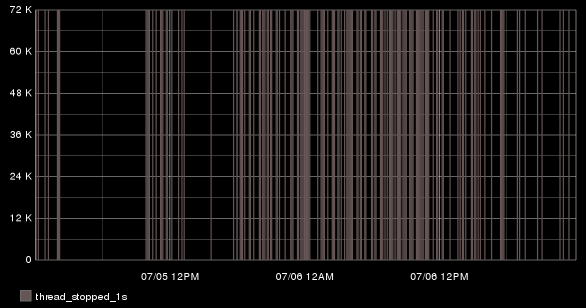
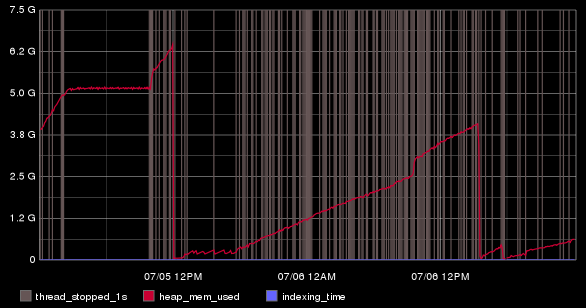
AWESOME, RIGHT?!@#!@? I know. So, first off, drawAsInfinite is awesome. How awesome? Well, I'll tell you. Any value greater than zero is displayed as vertical line on your graph. Sounds neat right? Combine that with the offset function and you can strike a vertical line anywhere on the graph where a data point is greater than a certain value.
In the above graph, I've chosen to mark a vertical line anywhere the JVM paused for greater than 1 second with a vertical line. BUT WAIT! ES output MILLISECONDS, and a lot of times it's pausing for only just a few milliseconds or even nano seconds. Enough to be greater than 1, but too low for me to care. I really want to know when the JVM pauses for more than 1 second, so I extract and graph that data like so:
drawAsInfinite(offset(nonNegativeDerivative(es.searchnode-01.jvm.gc.time_ms), -1000))
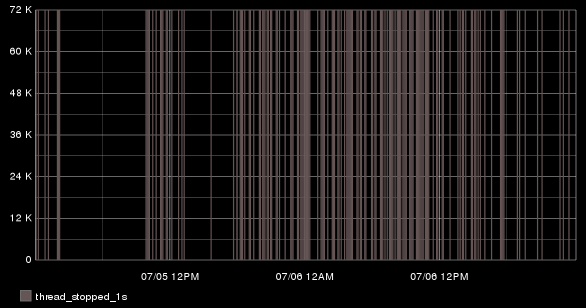
ES reports total time spent in GC as counter, so we use nonNegativeDerivative to extract the changes. Since we're in milliseconds, we substract 1,000 and now only data points with 1 second or higher will be displayed. That by itself is interesting, but where it gets fun is when you start correlating that data with other events.
I added the red line, which is the size of the JVM Heap:
color(es.searchnode-01.jvm.mem.heap.used_bytes,"red")
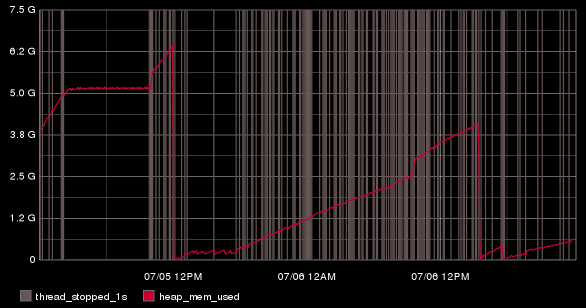
That was interesting, but this box is doing a lot of indexing as it's receiving my log data, so it can easily hit 7-8,000 messages per second. So I wanted to graph time spent indexing along with these points. The ES tracker keeps a counter of the time, which increments until restarts which you can see by drops here:
es.searchnode-01.indices.indexing.time_ms
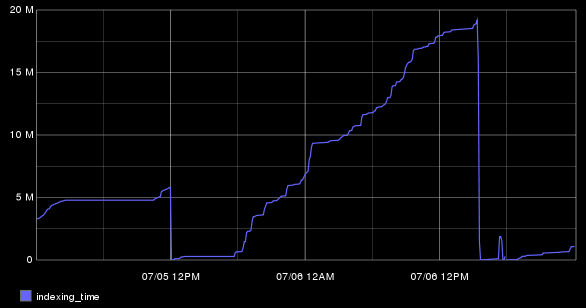
No worries, using the derivative or nonNegativeDerivative functions you extract the change and graph the line. Since we have restarts, we're going to use the nonNegativeDerivative function to ignore the drops:
nonNegativeDerivative(es.searchnode-01.indices.indexing.time_ms)
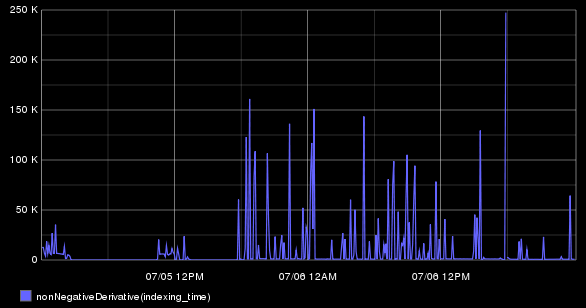
When we add this back into the graph, you'll notice that the line hugs the X axis pretty tightly:
This is mainly because that number is so small compared to the bigger JVM Heap numbers. No worries, we'll call secondYAxis to cram as much data into these pixels as we can!
secondYAxis(derivative(es.searchnode-01.indices.indexing.time_ms))
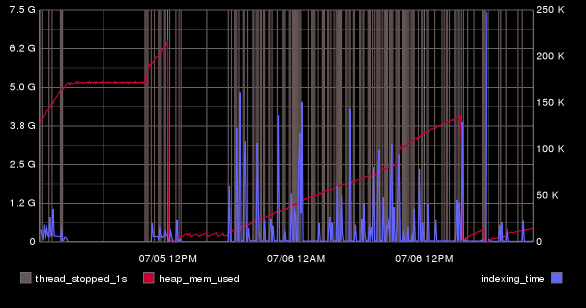
Yay!